PFH
Point Feature Histogram
아무리 검색을 해도 PFH에 대한 한국어 검색 결과를 찾을 수 없어서, 직접 공부한 후 정리하기로 했다.
아마 PFH에 대해 공부를 할 정도의 사람이면, 영어로 된 레퍼런스를 뒤져 정보를 얻는데 익숙하기 때문에 구태여 한글로 정리된 문서가 필요 없었던 것 같다.
PFH는 무엇인가?
Point Feature Histogram의 약자로, xyz좌표로 이루어진 Point cloud에서 특징을 추출할 때 사용된다.
histogram을 기반으로 특징을 서술하는 descriptor이며,
Point cloud에서 특징을 추출할 때 주로 사용되는 FPFH의 기반알고리즘이다.
인접한 포인트들의 법선벡터 및 거리를 이용하여 histogram을 만든 후 특징으로 사용한다.
16개의 bin을 가진 histogram데이터가 point에 대한 특징이 된다.
PFH의 알고리즘 절차
우선 어떤 절차를 통해 알고리즘이 진행되는지 나열한 후 상세하게 설명하겠다.
1. 특정 point t로부터 일정 반경 이내의 모든 point 선택
2. 선택된 모든 point를 pair으로 연결함

-----------------모든 pair에 대해서 반복------------
pair는 Ps와 Pt 2개의 point로 이루어짐
3. PCA를 통해 각각의 normal을 구함
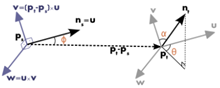
4. Pt와 Ps의 좌표, normal을 이용해서 Darboux Frame을 정의함
5. Darboux Frame과 Pt의 normal을 사용해서 f1, f2, f3, f4값을 얻는다.
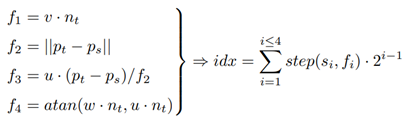
여기서 step(Si, Fi)는 단위 계단함수이고, Si는 Threshold라고 생각하면 된다.
Fi값이 Si값보다 작으면 0, 크면 1이다.
6. idx값을 16-bin histogram에 추가한다.
-----------------------------------------반복 끝------------------
7. histogram의 값을 읽어 필요한 곳에 사용한다.

input - point cloud (raw data), radius (인접 point를 구할 반경)
output - 16-bin histogram
PFH위와 같은 절차로 이루어진 알고리즘이다.
간단하게 순서를 나열하기 위해 생략된 내용도 많고, 처음보는 키워드가 많아 이해하기 힘들 수도 있다.
이제부터는 위 7과정을 천천히 설명해보겠다.
1. 특정 point t로부터 일정 반경 이내의 모든 point 선택
Point cloud는 이미지와 다르게 특징을 추출하기 위해서 curvature과 normal을 이용한다.
point cloud에서 특징을 뽑는 PFH도 마찬가지로 point들에 대해서 normal을 구해야한다.
하지만 다들 알고있다시피 normal과 curvature는 여러개의 점을 통해 구성되는 개념으로 1개의 point로는 얻을 수 없다.
그래서 일반적으로 특정 point t에 대해서 normal을 얻을 때는 t로부터 일정반경 이내의 모든 점을 얻고,
그 점들로 평면을 만들어 normal을 구하게 된다.
인접 point는 k-neighborhood를 통해서 구하고,
인접 point를 사용해서 평면을 만들 때는 PCA(principal Component Analysis)를 사용한다.
3. PCA를 통해 각각의 normal을 구함 ~ 4. Pt와 Ps의 좌표, normal을 이용해서 Darboux Frame을 정의함
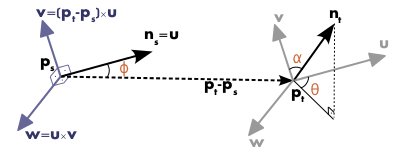
우리는 Ps, Pt로 이루어진 pair에 대해서 연산을 수행하고, 특징이라고 할 수 있는 차이점을 추출해야한다.
그래서 feature descriptor는 1. 어떤 특징을 사용할 것인가, 2. 어떻게 특징을 저장할 것인가.
이 두 가지에 대해서 명확하게 정의해야 한다.
PFH는 4개의 차이점을 이용해서 16-bin histogram을 통해 특징을 저장한다.
4개의 차이점은 매우 간단하다.
위 그림을 보면 비교 대상인 Ps와 Pt 두 점에 대해서 각각 normal을 구했는데,
이 normal간의 차이가 데이터가 된다.
우선 Ps의 normal과 Pt, Ps의 위치 데이터를 사용해서 Darboux Frame을 정의한다.
Darboux Frame은 특정 표면에서의 moving frame인데, 아래 사진을 보면 바로 이해할 수 있을것이다.

정의한 UVW좌표계와 normal, point들의 위치 좌표를 사용해서 4개의 차이점인 f1~4를 구한다.
여러가지 수식이 쓰여있지만 이해하기 쉽게 간략하게 표현하자면
Ps와 Pt의 normal 각도차이 3개와 Ps, Pt사이의 거리 1개를 합쳐 4개의 데이터이다.
그리고 이 데이터들을 각각의 step함수에 넣고 더하는데, fi값이 si값보다 작을 경우는 0, 클 경우는 1을 반환한다.
si값은 각각 특징에 대한 Threshold값이라고 생각하면 된다.
이 때 특징값에 2^(i-1)을 곱하게 되는데,
이로서 이 단위계단 함수는 2진법에서 flag역할을 하게된다.
즉 f1만 Threshold보다 크고 나머지 값들이 작으면
0001 ->1
f1과 f3값만 Threshold보다 크다면
0101 ->5
모든 값들이 Threshold보다 크다면
1111 ->15
이런 식으로 0부터 15까지의 값을 idx로 반환해주는 것이다.
예상했을수도 있겠지만, 이렇게 구해진 idx들 값들이 histogram의 bin이 되어 histogram을 그리게된다.
7. histogram의 값을 읽어 필요한 곳에 사용한다.

Plane, Cylinder 등 여러 곡률을 가진 물체에서 얻은 hitsogram이다.
이러한 histogram은 물체의 곡률에 따라 특정한 분포를 보이는데, 이 분포들을 통해서 물체의 곡률을 판단해 특징으로 사용하게된다.
여담이지만 논문의 필자는 step함수에서 더 자세한 특징을 뽑기위해 0,1이 아닌 0,1,2를 사용해서 시도해보려 했지만 step함수에서 3개의 결과를 출력하면 3^4=81개의 histogram bin이 추출되어 2개의 결과만을 사용했다고 한다.
step함수의 결과를 늘려가며 출력한 데이터를 비교하는 것도 재미있는 논문 주제가 될 수 있을 것 같다.
이 논문을 보며 궁금한 것이 있다면 f1~4의 차이점인데,
왜 직접 normal의 각도 차이를 사용하지 않고 내적 연산을 거친 값을 비교 데이터로 사용했는지 궁금하다.
나중에 더 연구해볼 예정이다.
참고 문헌 및 사이트
Radu Bogdan Rusu, Zoltan Csaba Marton, Nico Blodow, Michael Beetz, "Persistent Point Feature Histograms for 3D Point Clouds", In Proceedings of the 10th International Conference on Intelligent Autonomous Systems (IAS-10), Baden-Baden, Germany, 2008.
PCL library robotica.unileon.es/index.php/PCL/OpenNI_tutorial_4:_3D_object_recognition_(descriptors)#RSD