kernel density estimation은 대표적인 Non-paramatic 밀도 추정 방법중 하나이다.
커널 밀도 추정은 밀도를 추정하는 방법 중 커널 함수를 이용하는 하나의 방법이고,
그렇기때문에 커널 밀도 추정을 이해하려면 우선 밀도추정에 대해서 이해해야 한다.
그리고 추가로 아래 내용에 대한 대략적인 기초지식이 필요하다.
확률변수, 확률 밀도함수, 분포, 적분 etc...
Density estimation
밀도 추정을 이해하기 쉽게 설명하자면, 추출된 데이터들을 통해서 확률 밀도함수를 구하는 행위이다.
확률 밀도함수는 확률 변수의 분포를 나타낸 함수인데,
구간 [a, b]에서 확률변수 X가 해당 구간에 있을 확률을

로 나타낸 함수이다.
즉, 정의역과 치역이 양수이고, 함수를 적분한 결과가 1이며 확률변수 x가 대략적으로 f(x)값을 가지게 되는 함수이다.
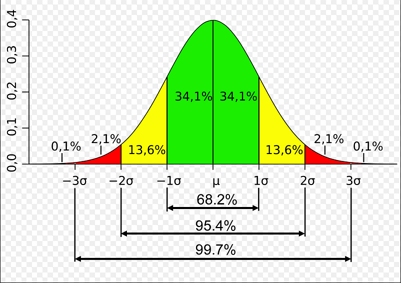
위 그래프로 설명하자면, 특정한 사건 P에서, x라는 값을 선택했을 때 x가 μ~1σ일 확률은 34.1%이고, 2σ~3σ일 확률은 2.1%인 것이라고 생각하면 쉽다.
또 다른 예를 들면 차량 통행량이 있다.
월요일의 아침부터, 일요일 밤까지 24시간 365일 특정 구간의 차량 통행량 데이터를 집계한다면, 평균 데이터를 얻어서 1주일을 주기로 histogram을 만들 수 있다. 그렇다면 우리는 이 데이터를 통해 대략적으로 어느 시간대에 차량이 많이 통행하는지, 적게 통행하는지 알 수 있고, 그 데이터를 역으로 활용한다면 차량 한 대가 이 도로를 지나간다고 했을 때, 어떤 요일의 어떤 시간대에 통행했을 확률이 몇%인지 구할 수 있다.
이것이 Dessity estimation(밀도추정)이다.
다시한번 정리하자면, Density estimation이란, 특정한 사건에서 추출된 일부분의 데이터의 통계를 사용해서, 확률 밀도함수의 분포를 파악하는 추정법인 것이다.
이러한 밀도추정 방법은 다양한 종류가 존재하는데, 크게 parametic estimation과, Non-parametic estimation으로 나뉜다. - 이번 포스트의 메인 주제가 아니니 이 분류에 대해서는 다른 포스트에서 다루도록 한다.
parametic estimation의 대표적인 추정법에는 Maximum likelihood estimation이 있고(링크),
Non-parametic estimation의 대표적인 추정법에는 본문의 주제인 Kernel density estimation이 있다.
Kernel density estimation
드디어 kernel에 대해 언급할 수 있게 되었다.
kde는 수많은 추정법중 kernel function을 이용한 density estimation이다.
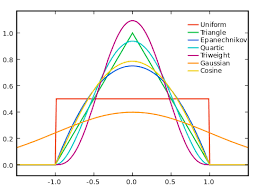
kernel function의 정의는 3가지로 정리할 수 있다.
1. 적분값이 1이다.
2. 중앙을 기준으로 대칭이다.
3. 양수값만을 가진다.
위와 같은 kernel function을 통해서 전체 데이터의 분포를 예측하는데,

다음과 같은 수식을 사용한다.
K는 위에서 본 kernel 함수이고, h는 커널함수의 bandwidth값으로 커널의 분산을 조절하는 파라미터이다.
h값이 작을수록 커널이 뾰족한 형태를 띄고, 클수록 커널이 완만한 형태가 된다.
위 식은 매우 복잡해보이지만 그래프로 확인하면 매우 쉬운 개념이다.

왼쪽 그래프의 히스토그램은 오른쪽 그래프의 빨간색 부분으로 커널함수가 생성되고, 이 함수들을 모두 컨볼루션 하면 kde를 얻을 수 있다.