2010년 이후 컴퓨터의 연산능력과 병렬처리 기술이 급격히 상승하며 딥러닝은 이상적인 이론에서 현실의 문제를 해결하는 방법론으로 자리를 잡아갔다. 오늘 리뷰할 논문의 주제도 마찬가지다. 간략하게 정의하자면 딥러닝의 신경망으로 3D point cloud사용할 때의 몇몇 문제점을 해결해서 효과적으로 poinc cloud데이터를 classify하고 segmentation하는 것이 주요 골자이다.
2017년 CVPR에서 발표되었고, projection시키거나 voxelize하지 않고 point cloud의 raw데이터를 그대로 사용하는 딥러닝 기반 방법론의 baseline이 되었다.
Introduction
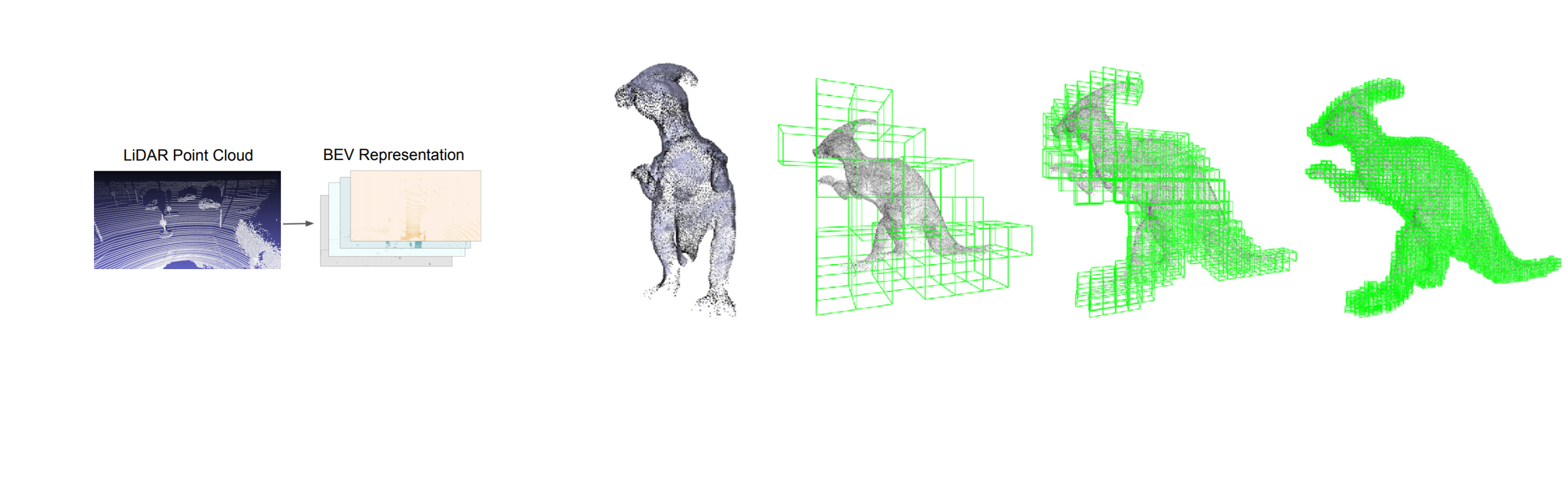
전통적인 convolutional 구조는 규칙적인 data format을 기반으로 했다. 주로 height별로 slice된 BEV(bird eye's view) 를 활용하거나, voxelize해서 신경망의 입력데이터로 활용했다. 하지만 point cloud 데이터는 2D 이미지와는 다르게 빈공간이 많아 매우 비효율적이고, 사용하기 위해서 전처리 과정을 거쳐야한다. 그래서 이 논문에서는 딥러닝 신경망에 point cloud를 raw data그대로 활용하기 위한 방법론을 제시했다.
딥러닝 신경망에 point cloud를 가공하여 입력하면 3가지의 단점이 있다.
첫 번째로는 데이터가 불필요하게 크다. 이미지와는 다르게 pointcloud는 빈공간이 많아 모든 공간을 활용할 필요가 없다. 하지만 복셀화 한 데이터나 이미지를 컨볼루전 하면 빈공간의 의미없는 연산이 반복된다.
두 번째는 특징의 손실이다. raw data를 가공하는 과정에서 필연적으로 데이터의 변화가 일어날 수밖에 없다.
마지막은 전처리과정 연산비용이다. 데이터를 가공하는 과정에서 사용하는 모든 연산비용이 포함된다.
Problem Statement
논문의 저자는 point cloud raw data를 그대로 딥러닝 신경망에서 활용하기 위해서는 point cloud의 3가지 성질이 고려되어야 한다고 말한다.
1. Unordered
2. Interaction among points
3. Invariance under transformation
1. Unordered
point cloud는 픽셀이나 복셀과 다르게 정렬되어있지 않다. point cloud는 기본적으로 순서가 없는 point들의 집합이다. (point cloud is a set of pointswithout specific order.) 정렬될 것 같이 느껴지지만, 쉬운 반례를 통해 왜 불가능한지 알아보자.
만약 point cloud를 정렬할 수 있는 특정한 정렬방법이 존재한다면, 그것은 고차원 공간에서 1차원 선상으로 전단사 매핑(bijection map)을 정의한 것이다. 이것은 차원 감소에 의해 spatial proximity를 보존해줘야 하지만, 알다시피 pointcloud의 정렬을 통해 spatial proximity를 보존하는 것은 불가능하다.
2. Interaction among points
위에서 말했던 spatial proximity와 매우 밀접한 관계이다. pointcloud는 다른 데이터와의 distance 정보만을 통해서 의미를 갖는 다는 뜻이다.
예를 들자면 픽셀은 U, V 라는 좌표에서 특정한 value를 가진다. 그것은 rgb일 수도 있고, grayscale일 수도 있다. 하지만 pointcloud는 X, Y, Z라는 좌표에서 존재한다는 value만 가지게된다. 즉, 해당 좌표의 value를 통해 특징을 가질 수 있는 픽셀과 다르게 pointcloud는 value를 통해 의미를 찾을 수 없고, 다른 데이터들과의 distance를 통해 의미를 찾아야 한다는 뜻이다.
3. Invariance under transformation
이 부분은 pointcloud 뿐만 아니라 현실세계의 대부분의 sementic한 데이터에 통용되는 것으로, 데이터들이 평행이동하거나, 회전해도 그 데이터들이 가지는 의미는 같다는 뜻이다.
자동차를 거꾸로 뒤집어놓아도 자동차로 인식해야하고, 책상이 30도쯤 회전해있어도 책상으로 인식해야 한다는 뜻이다.
저자는 이 3가지의 특성을 모두 고려한 알고리즘을 설계하는것이 중요하다고 한다.
Method
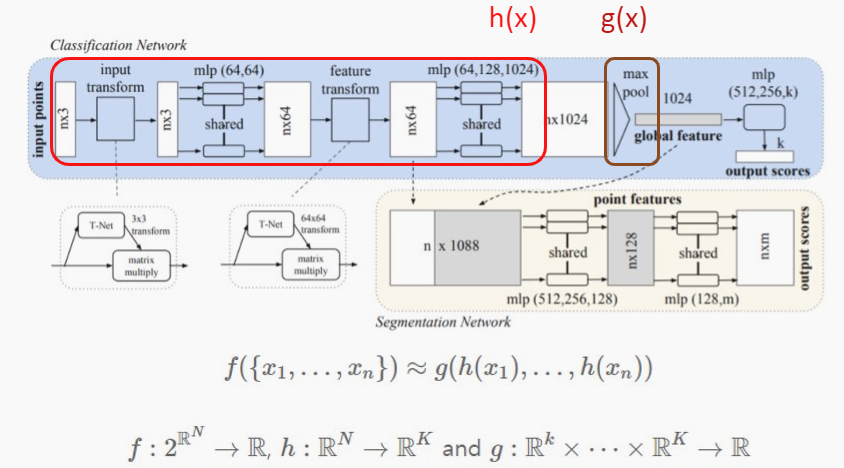
Unordered 문제는 symmentic function을 사용함으로서 해결했다. symmentic function이란 +나 x같이 입력 순서에 변화가 생기더라도 결과값이 바뀌지 않는 함수이다. 이 논문에서는 symmentic function의 종류로 max pooling을 사용했다.
n개의 point에서 x, y, z 3개의 데이터를 받은 후, 1024개의 특징을 추출하고, n * 1024 개의 특징을 1024개로 max pooling한다. max pooling 과정을 거치면 n의 내부에서 데이터가 어떤 순서로 존재하는지에 관계없이 같은 결과가 나오게 된다.
--중략



